Introduction to d2s
This documentation explains how to use the d2s Command Line Interface to deploy services to integrate and access data in a Knowledge Graph:
- Integrate any structured data using various solutions.
- Deploy various interfaces to consume the Knowledge Graph data.
- Deploy user-friendly web UI to access the integrated data.
Not maintained anymore
We are currently migrating from the CLI to using more GitHub Actions workflow, the d2s CLI is not maintained anymore. Prefer using the documentation at Publish data and Deploy services
d2s is a Command Line Interface, written in Python, that helps you define download scripts, metadata, mappings and Jupyter notebooks to integrate multiple datasets into a Knowledge Graph complying with a defined data model. d2s has been developed using mainly RDF Knowledge Graphs, but property graphs, such as Neo4j, can also be used.
This documentation is intended for people who are familiar with Docker and running simple commands in a Terminal. It is also preferable to be familiar with the SPARQL query language.
The d2s tool is following the Data2Services framework detailed in this figure:
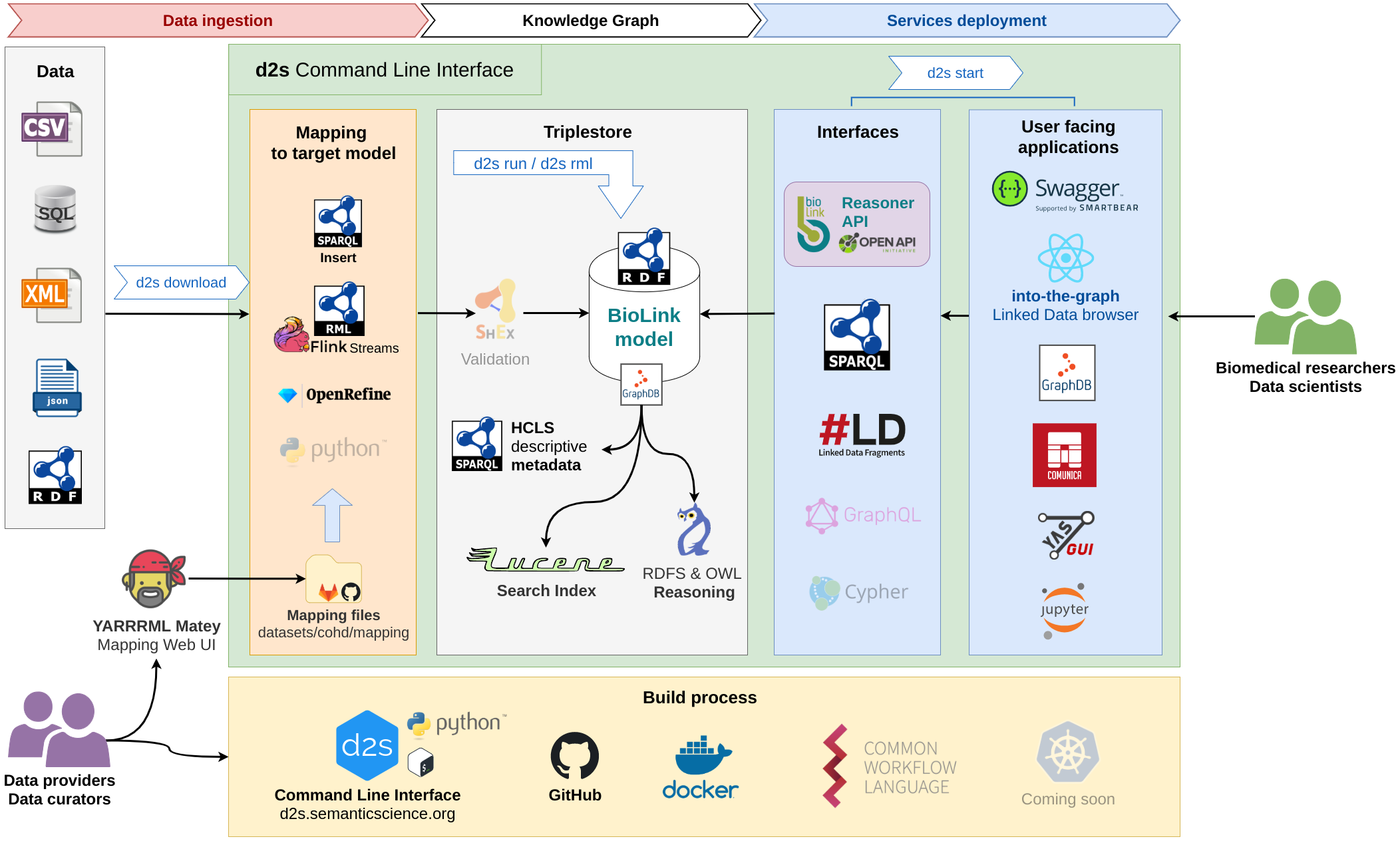
We provide d2s-project-template, a GitHub template repository with example mappings and workflows to start building your RDF Knowledge Graph from structured data.
Feel free to use directly the d2s-project-template repository or create a new GitHub repository from the template to start your own project.
See this presentation for more details about the Data2Services project.
Build a RDF Knowledge Graph#
- Initialize a
d2sproject - Add a new dataset
- Choose a solution to integrate your data
Multiple solutions available to integrate data in a standard Knowledge Graph:
RML mappings (RDF Mapping Language)
CWL workflows defined to convert structured files to RDF using SPARQL queries
BioThings Studio to build BioThings APIs (exposed to the Translator using the ReasonerStd API)
DOCKET to integrate omics data
Python scripts and notebooks, such as Dipper ETL, rdflib or pandas
Define new CWL workflows to build and share your data transformation pipelines
- It is strongly recommended to use a POSIX system (Linux, MacOS) if you consider running workflows on your laptop, since most workflow orchestration tools do not support Windows.
Deploy services#
Once your data has been integrated in a RDF Knowledge Graph you can deploy interfaces and services to access your data.
Data2Services aims to provide an exhaustive documentation to run and deploy RDF and Knowledge Graph related services using Docker. The d2s CLI uses docker-compose to start and link locally the different services.
Project folder structure#
The d2s client uses the following directory structure, which can be found in the example project d2s-project-template (here with the cohd dataset):
Source code repositories#
The Data2Services project uses multiples Git repositories:
- d2s-cli: A Command Line Interface to orchestrate the integration of heterogenous data and the deployment of services consuming the integrated data (Python).
- It will clone and use a d2s-project-template repository to store your project services and workflows settings.
- d2s-project-template: template to create a Data2Services project folder, with example mappings to a few datasets, it includes d2s-core as submodule.
- d2s-core (imported as submodule in d2s-project-template): CWL workflows to transform structured data to a target RDF model.
- d2s-docs: source code of this documentation.